Bert任务说明
Next Sentence Prediction
下一句预测
句子对分类任务
- MNLI
Williams等人[22]提出的多体自然语言推理(Multi-Genre Natural Language Inference)是一项大规模的分类任务。给定一对句子,目标是预测第二个句子相对于第一个句子是包含,矛盾还是中立的。
- QQP
Chen等人[23]提出的Quora Question Pairs是一个二分类任务,目标是确定在Quora上询问的两个问题在语义上是否等效。
- QNLI
Wang等人[24]出的Question Natural Language Inference是Stanford Question Answering数据集[25]的一个版本,该数据集已转换为二分类任务。正例是(问题,句子)对,它们确实包含正确答案,而负例是同一段中的(问题,句子),不包含答案。
- STS-B
Cer等人[26]提出的语义文本相似性基准(The Semantic Textual Similarity Benchmark)是从新闻头条和其他来源提取的句子对的集合。它们用1到5的分数来标注,表示这两个句子在语义上有多相似。
- MRPC
Dolan等人[27]提出的Microsoft Research Paraphrase Corpus由自动从在线新闻源中提取的句子对组成,并带有人工标注,以说明句子对中的句子在语义上是否等效。
- RTE
Bentivogli等人[28]提出的识别文本蕴含(Recognizing Textual Entailment)是类似于MNLI的二进制蕴含任务,但是训练数据少得多。
- SWAG
Zellers等人[29]提出的对抗生成的情境(Situations With Adversarial Generations)数据集包含113k个句子对完整示例,用于评估扎实的常识推理。给定一个句子,任务是在四个选择中选择最合理的连续性。其中,在SWAG数据集上进行微调时,我们根据如下操作构造训练数据:每个输入序列都包含给定句子(句子A)和可能的延续词(句子B)的串联。
如图 8.11(a)所示,句子对分类任务首先需要将两个句子用“[SEP]”连接起来,并输入模型。然后,我们给预训练模型添加一个简单的分类层,便可以在下游任务上共同对所有参数进行微调了。具体运算逻辑是引入唯一特定于任务的参数是分类层权重矩阵 ,并取BERT的第一个输入标记“[CLS]”对应的最后一层向量
。通过公式(8.4)计算分类损失loss ,我们就可以进行梯度下降的训练了。
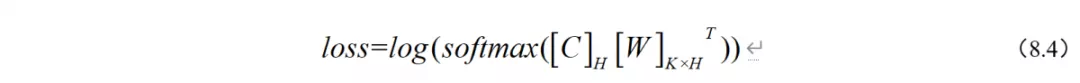
其中K为标签种类,H为每个字或者英文单词的隐藏层维度(768)。
单句子分类任务
- SST-2
Socher等人[30]提出的斯坦福情感树库(Stanford Sentiment Treebank)是一种单句二分类任务,包括从电影评论中提取的句子以及带有其情绪的人类标注。
- CoLA
Warstadt等人[31]提出的语言可接受性语料库(Corpus of Linguistic Acceptability)也是一个单句二分类任务,目标是预测英语句子在语言上是否“可以接受”。
问答任务
SQuAD v1.1:Rajpurkar等人[25]提出的斯坦福问答数据集(Stanford Question Answering Dataset)是10万个问题/答案对的集合。给定一个问题以及Wikipedia中包含答案的段落,任务是预测段落中的答案文本范围(start,end)。
单句子标注任务
单句子标注任务也叫命名实体识别任务(Named Entity Recognition),简称NER,常见的NER数据集有CoNLL-2003 NER[32]等。该任务是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。举个例子:“明朝建立于1368年,开国皇帝是朱元璋。介绍完毕!”那么我们可以从这句话中提取出的实体为:
(1) 机构:明朝
(2) 时间:1368年
(3) 人名:朱元璋
同样地,BERT在NER任务上也不能通过添加简单的分类层进行微调,因此我们需要添加特定的体系结构来完成NER任务。不过,在此之前,我们得先了解一下数据集的格式,如图 8.10所示。
它的每一行由一个字及其对应的标注组成,标注采用BIO(B表示实体开头,I表示在实体内部,O表示非实体),句子之间用一个空行隔开。当然了,如果我们处理的是文本含有英文,则标注需采用BIOX,X用于标注英文单词分词之后的非首单词,比如“Playing”在输入BERT模型前会被BERT自带的Tokenization工具分词为“Play”和“# #ing”,此时“Play”会被标注为“O”,则多余出来的“# #ing”会被标注为“X”。
了解完整体的数据格式,我们就开始了解整体的NER任务是如何通过BERT来训练的。如图 8.11(d)所示,将BERT最后一层向量 [C]LxH输入到输出层。具体运算逻辑是初始化输出层的权重矩阵[W]KxH ,此时K为1。我们通过公式8.5得到句子的概率向量logit ,进而知道了每一个字或者英文单词的标注概率。然后,我们可以直接通过计算 logit与真实标签之间的差值得到loss ,从而开始梯度下降训练。
Bert任务
BertForMaskedLM
Bert Model with a language modeling head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
BertForNextSentencePrediction
下任务一句
BertForSequenceClassification
句子分类
BertForMultipleChoice
Multiple choice(or multiple-choice questions)指提供给了答卷者多个“选项”,choice就是可供选择的不明对错的项目, as in “you have three choices”…所以严格意义上multiple choice是选择题的统称,包括了单选与多选,因为它没说明正确答案是否只有一个。
BertForTokenClassification
做ner实体标注
Bert Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
BertForQuestionAnswering
做问答任务
Bert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear layers on top of the hidden-states output to compute span start logits and span end logits). This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.Parameters